Motion-to-Text
Transforming Human Movements into Natural Language
Introduction
Understanding human motion and converting it into natural language is a complex challenge at the intersection of computer vision, deep learning, and natural language processing. This project introduces an autoencoder-based model that translates human motion sequences into textual descriptions using a Transformer-based Motion Encoder and a GPT-2-based Text Decoder.
Model Architecture
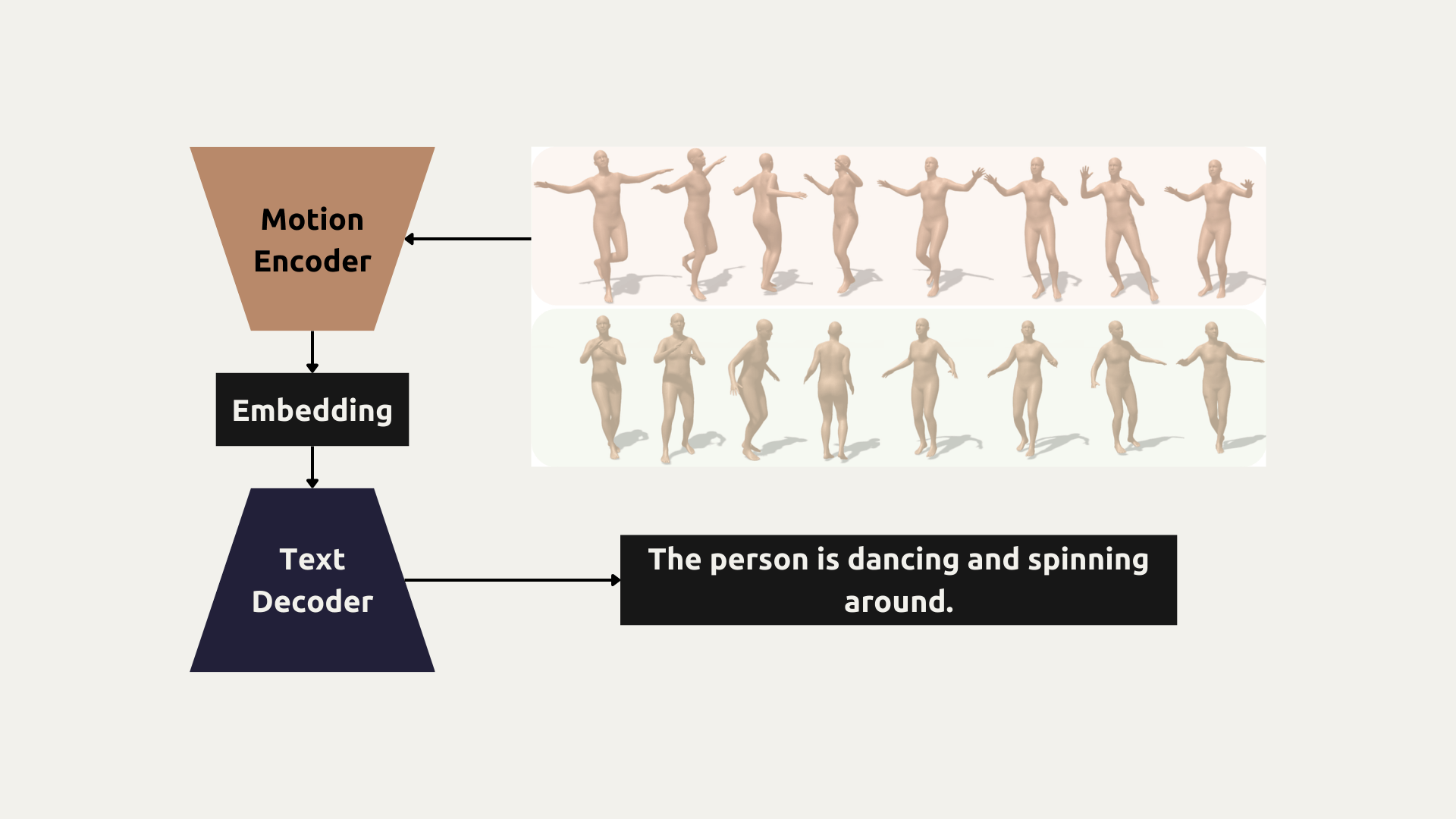
The model consists of three main components:
1. Motion Encoder Transformer
The Motion Encoder processes a sequence of human poses (joint positions over time) and encodes them into a latent representation:
- 1D Convolutions to capture local motion patterns
- Transformer Encoder to model long-range temporal dependencies
- Projection Layer to map motion representations to a format compatible with GPT-2
- L2 Normalization and Noise Injection to stabilize embeddings and improve generalization
Output: A 768-dimensional latent vector representing the motion.
2. Latent Space Representation
The latent space acts as an intermediate representation between motion and text:
- Dimensionality Reduction to condense motion data
- Noise Addition to improve robustness
- Transformation to GPT-2 Embeddings for smooth integration with the text decoder
This intermediate space is crucial for effective motion-to-text transformation.
3. Text Decoder with GPT-2
The Text Decoder generates coherent sentences from the latent motion representation:
- Latent-to-GPT-2 Projection to align motion embeddings with GPT-2’s format
- Cross-Attention Layer to refine context understanding
- Autoregressive Text Generation for natural sentence construction
- Controlled Generation using temperature, top-p sampling, and repetition penalties
Example Output:
“A person walks forward and picks something up with their right hand.”
Training Strategy
The training process is divided into two phases:
1. Pretraining Motion Encoder
- GPT-2 is frozen for the first four epochs to stabilize motion embeddings
- Layer Normalization & Weight Decay to avoid gradient explosion
- ReduceLROnPlateau Scheduler to adjust learning rate dynamically
2. Fine-Tuning GPT-2
- Gradual Unfreezing of GPT-2 for better adaptation
- Scheduled Sampling replaces 10% of ground-truth tokens with model predictions for robustness
- Gradient Clipping to prevent unstable updates
This approach steadily improves the BLEU score and text coherence.
Results & Key Takeaways
- Improved Text Quality: The model generates concise and natural descriptions
- Higher BLEU Score: Optimized training strategies enhance fluency
- Better Generalization: Noise injection prevents overfitting to specific motion patterns
- More Robust Predictions: Cross-attention improves motion understanding
Next Steps
- Extending the model to 3D motion datasets
- Improving diversity in sentence generation
- Exploring real-time motion captioning for applications in AR/VR
This project represents a step forward in bridging human motion and language, with potential applications in action recognition, robotics, and accessibility.